MGnify JBrowse
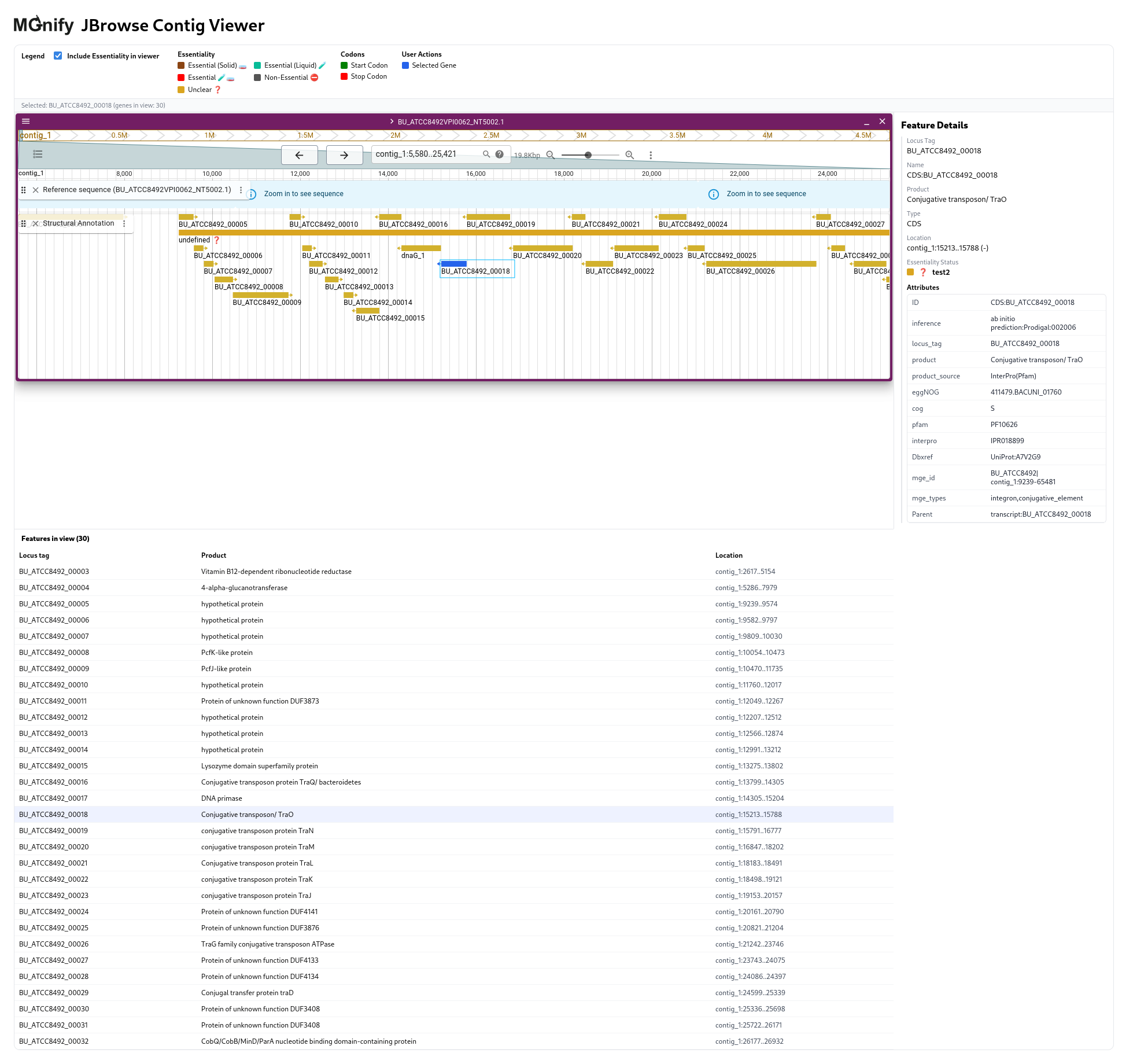
MGnify JBrowse is a React component library which embeds the JBrowse genome viewer to allow users to view the genome sequence (FASTA), structural annotation, and functional information (GFF).
The viewer supports millions of gene or protein features through efficient data loading and virtualized rendering. Its architecture builds on standard genomic formats—GFF for annotations and FASTA for sequences—and optionally merges auxiliary functional annotation from backend services. The current implementation integrates with a Django + Elasticsearch backend for scalable querying, though the frontend can operate independently with any compatible APIs.
Our initial aims over the course of the hackathon were to:
- Test the viewer using new data
- Evaluate performance and identify bottlenecks/edge cases
- Improve documentation and configuration options
- Stretch goal: A complete plug-and-play app where users can drag and drop their own data for visualisation
What we did over the course of the hackathon:
- Tried new data and identified (and fixed) issues arising
- New bacterial species (Strep pneumo, N. gono) with smaller genomes
- Smaller (but within ’normal’ for bacteria) genomes are too small to load in chunks → load entire genome at once
- Raised an issue with JBrowse team, they are working on a fix
- Large eukaryotic genomes tested for the first time (Dictyostelium, 200mbp, and Wheat, 15gbp)
- tabix indices only support contigs up to ~550mbp → Use .csi formatted tabix index
- Novel data tests revealed issues with parsing some (within spec) GFF formats
- De novo bacterial annotation, introns/exons in eukaryotes → switch to hierarchical gene/CDS visualisation
- New bacterial species (Strep pneumo, N. gono) with smaller genomes
- Automating index generation so users don’t need to run command line tools on their data before visualising
- Re-implement hstlib components
tabixandfaidxin webassembly so they can run in the browser - Almost done,
faidxworking,tabixis not producing identical output to hstlib at the moment
- Re-implement hstlib components
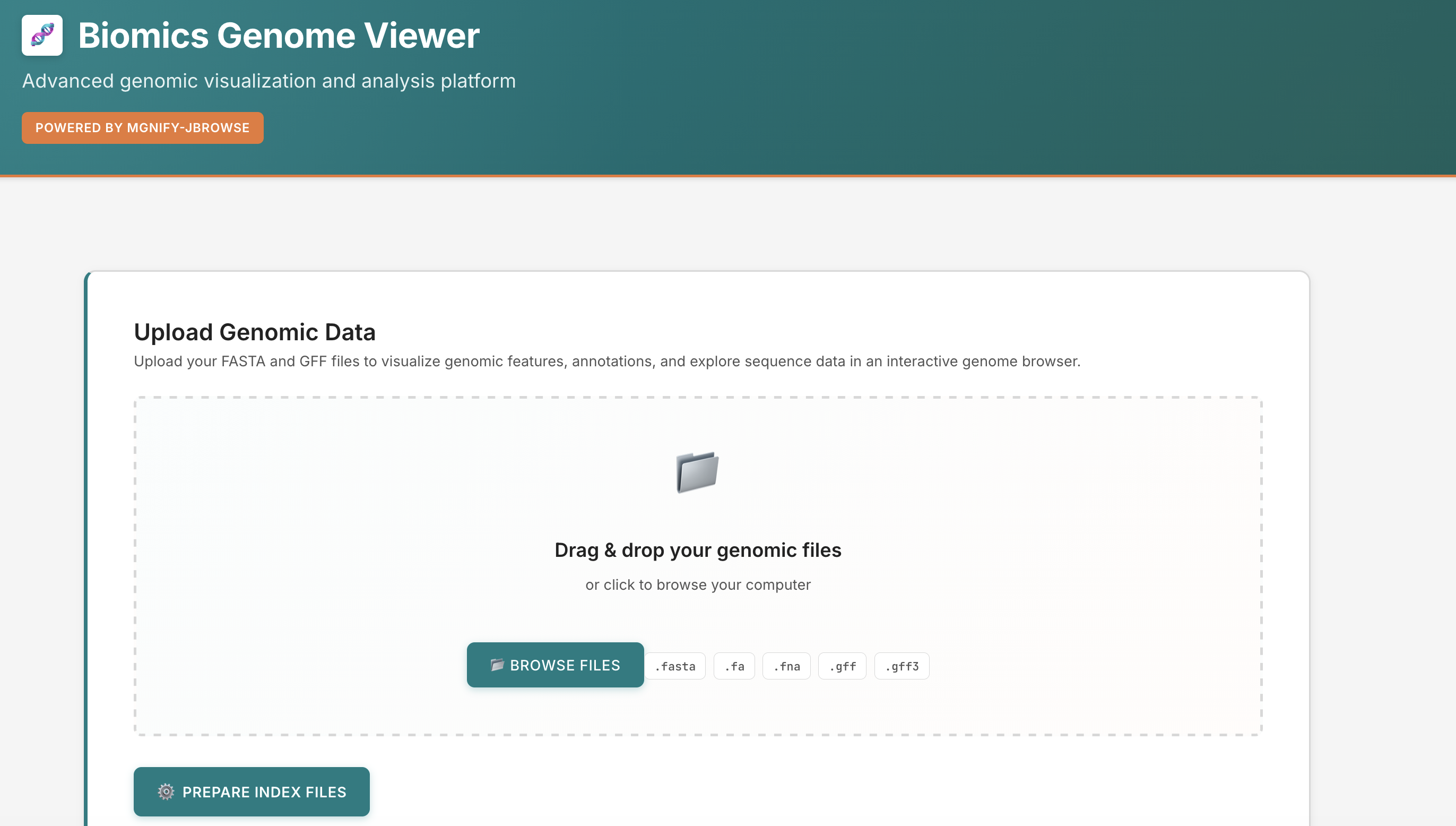
- Stand alone react app for users to input data using drag and drop
- Fully functional, just needs integration with the webassembly automated index generation!
What we didn’t do:
- Performance profiling
- 15gbp Wheat genome worked well - 800mbp chromosome, many thousands of features in view → low priority
How we felt about the hackathon format:
- Useful in bringing together data users and developers to identify limitations
- Split into one pair (react app), and individuals (wasm, debugging, testing new genomes)